Some Recent Advancement Around MuZero
Published:
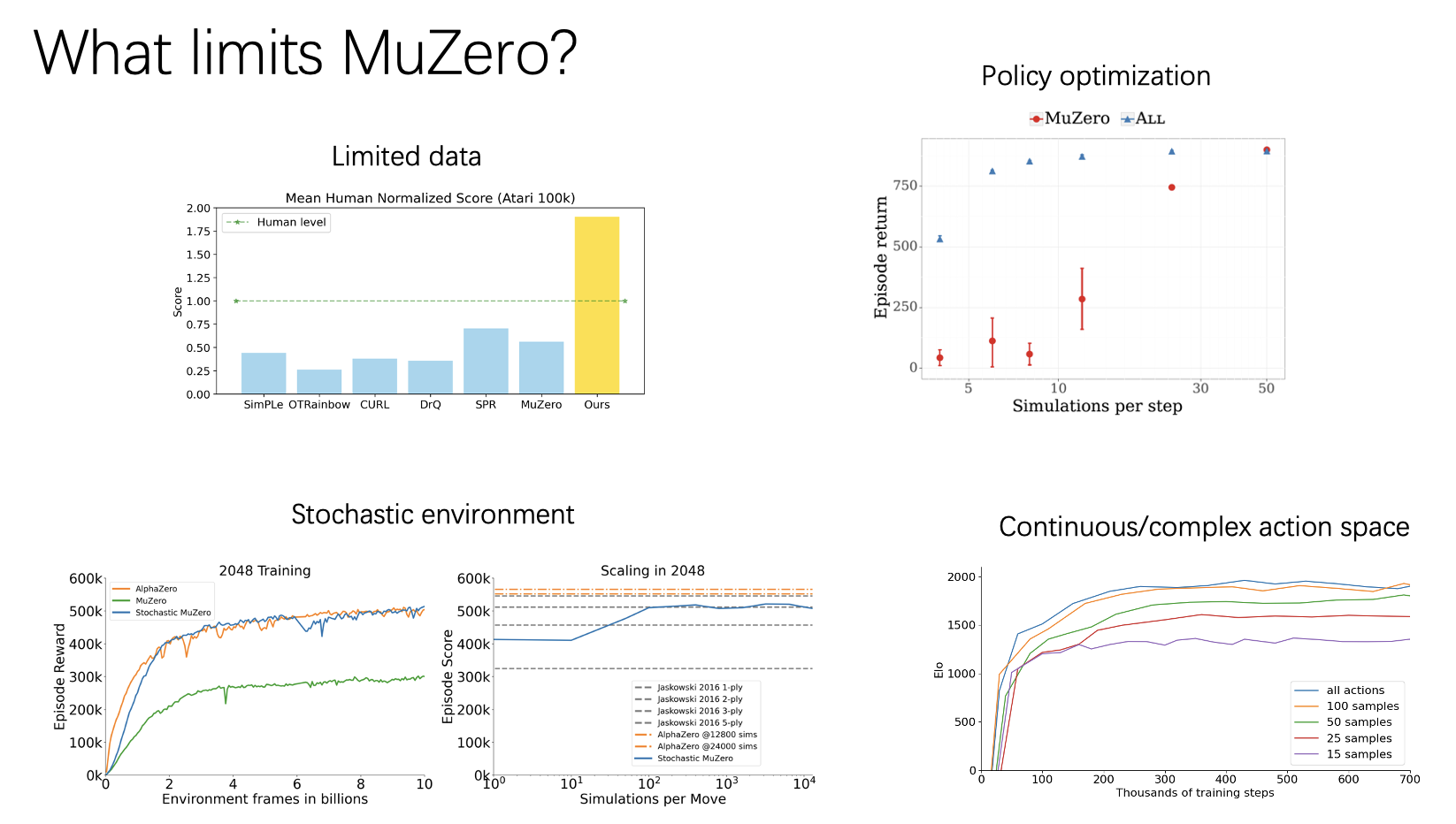

Published:
Published:
In a recent project for MECS6616 Robot Learning, I got hands-on experience for Model Predictive Control (MPC). To solve the problem, the use of constant action and pseudo-gradient is a recommended method, and it truly provides simple yet good enough solutions. However, the project instructions also hinted at another prospect: a differentiable forward model could help, since you can always compute numerical gradients. This piqued my curiosity - could we directly compute the gradient with respect to action given the evaluation metric? And if so, how could we implement this practically?
Published:

Muax provides help for using DeepMind’s mctx on gym-style environments.
Published:
This week, I will share a paper published by OpenAI at NeurIPS 2017. The ideas presented in this paper are quite insightful, and it tackles a complex problem using only simple algorithmic improvements. I gained significant inspiration from this paper. At the end, I will also provide a brief implementation of HER (Hindsight Experience Replay).
Published:
This week, I would like to share a paper published at NeurIPS 2021. When dealing with tabular data, I often find myself perplexed. On one hand, I am unsure which deep learning frameworks are better suited for this task, and on the other hand, I am uncertain whether the time-consuming process of training a model can outperform the easily accessible GBDT family of models such as XGBoost and LightGBM. However, this paper provides a detailed and comprehensive comparison of deep learning algorithms and GBDT models on tabular data. It introduces new baselines and presents a novel architecture that outperforms other deep learning models. I have gained a lot from this paper and would like to share it with you.
Published:
Can deep reinforcement learning algorithms be used to train a trading agent that can achieve long-term profitability using Limit Order Book (LOB) data? To answer this question, this article proposes a deep reinforcement learning framework for high-frequency trading and conducts experiments using limit order data from LOBSTER with the PPO algorithm. The results show that the agent is able to identify short-term patterns in the data and propose profitable trading strategies.