Adding MuZero into RL Toolkits at Ease
Published:

MUAX 😘
Muax provides help for using DeepMind’s mctx on gym-style environments.
Installation
You can install the released version of muax through PyPI:
pip install muax
Getting started
Muax provides some functions around mctx’s high-level policy muzero_policy. The usage of muax could be similar to using policies like DQN, PPO and etc. For instance, in a typical loop for interacting with the environment, the code is like(code snippet from muax/test):
random_seed = 0
key = jax.random.PRNGKey(random_seed)
obs, info = env.reset(seed=random_seed)
done = False
episode_reward = 0
for t in range(env.spec.max_episode_steps):
key, subkey = jax.random.split(key)
a = model.act(subkey, obs,
num_simulations=num_simulations,
temperature=0.) # Use deterministic actions during testing
obs_next, r, done, truncated, info = env.step(a)
episode_reward += r
if done or truncated:
break
obs = obs_next
Check cartpole.ipynb for a basic training example(The notebook should be runnable on colab).
1.To train a MuZero model, the user needs to define the representation_fn, prediction_fn and dynamic_fn with haiku. muax/nn provides an example of defining an MLP with single hidden layer.
import jax
jax.config.update('jax_platform_name', 'cpu')
import muax
from muax import nn
support_size = 10
embedding_size = 8
num_actions = 2
full_support_size = int(support_size * 2 + 1)
repr_fn = nn._init_representation_func(nn.Representation, embedding_size)
pred_fn = nn._init_prediction_func(nn.Prediction, num_actions, full_support_size)
dy_fn = nn._init_dynamic_func(nn.Dynamic, embedding_size, num_actions, full_support_size)
2.muax has built-in episode tracer and replay buffuer to track and store trajectories from interacting with environments. The first parameter of muax.PNStep (10 in the following code) is the n for n-step bootstrapping.
discount = 0.99
tracer = muax.PNStep(10, discount, 0.5)
buffer = muax.TrajectoryReplayBuffer(500)
3.muax leverages optax to build optimizer to update weights.
gradient_transform = muax.model.optimizer(init_value=0.02, peak_value=0.02, end_value=0.002, warmup_steps=5000, transition_steps=5000)
4.Now we are ready to call muax.fit function to fit the model to the CartPole environment.
model = muax.MuZero(repr_fn, pred_fn, dy_fn, policy='muzero', discount=discount,
optimizer=gradient_transform, support_size=support_size)
model_path = muax.fit(model, 'CartPole-v1',
max_episodes=1000,
max_training_steps=10000,
tracer=tracer,
buffer=buffer,
k_steps=10,
sample_per_trajectory=1,
num_trajectory=32,
tensorboard_dir='/content/tensorboard/cartpole',
model_save_path='/content/models/cartpole',
save_name='cartpole_model_params',
random_seed=0,
log_all_metrics=True)
The full training script:
import muax
from muax import nn
support_size = 10
embedding_size = 8
discount = 0.99
num_actions = 2
full_support_size = int(support_size * 2 + 1)
repr_fn = nn._init_representation_func(nn.Representation, embedding_size)
pred_fn = nn._init_prediction_func(nn.Prediction, num_actions, full_support_size)
dy_fn = nn._init_dynamic_func(nn.Dynamic, embedding_size, num_actions, full_support_size)
tracer = muax.PNStep(10, discount, 0.5)
buffer = muax.TrajectoryReplayBuffer(500)
gradient_transform = muax.model.optimizer(init_value=0.02, peak_value=0.02, end_value=0.002, warmup_steps=5000, transition_steps=5000)
model = muax.MuZero(repr_fn, pred_fn, dy_fn, policy='muzero', discount=discount,
optimizer=gradient_transform, support_size=support_size)
model_path = muax.fit(model, 'CartPole-v1',
max_episodes=1000,
max_training_steps=10000,
tracer=tracer,
buffer=buffer,
k_steps=10,
sample_per_trajectory=1,
num_trajectory=32,
tensorboard_dir='/content/tensorboard/cartpole',
model_save_path='/content/models/cartpole',
save_name='cartpole_model_params',
random_seed=0,
log_all_metrics=True)
5.After the training is done, one can use tensorboard to check the training procedure.
%load_ext tensorboard
%tensorboard --logdir=tensorboard/cartpole
In the figure below, the model is able to solve the environment in ~500 episodes, ~30k updates 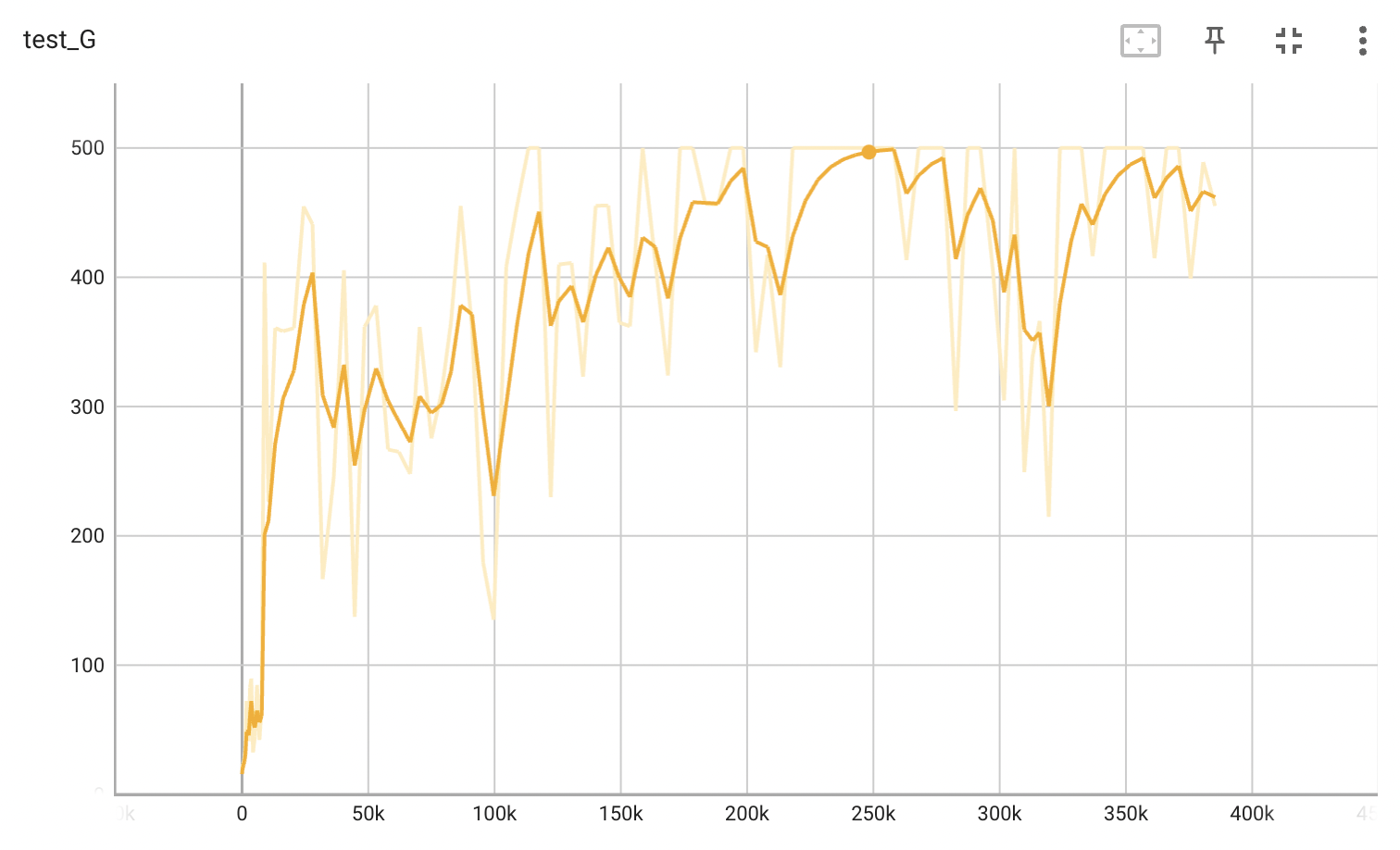
6.We can also have more tests with the best parameter
from muax.test import test
model = muax.MuZero(repr_fn, pred_fn, dy_fn, policy='muzero', discount=discount,
optimizer=gradient_transform, support_size=support_size)
model.load(model_path)
env_id = 'CartPole-v1'
test_env = gym.make(env_id, render_mode='rgb_array')
test_key = jax.random.PRNGKey(0)
test(model, test_env, test_key, num_simulations=50, num_test_episodes=100, random_seed=None)
Alternatively, the users could easily write their own training loop. One example is from cartpole.ipynb
More examples can be found under the example directory.