
MUAX
mcts-based reinforcement learning has been shown to be highly effective on tasks where planning is required. Recent work also showcased its ability on Atari games, which was previously considered to be hard for model-based reinforcement learning algorithms to achieve the same level performance of model-free algorithms. However, due to its root in board games, most implementation follows the system design of board game AI, which presents non-trivial difficulties to extend to wider range of reinforcement learning tasks. In this portfolio I present Muax, a flexible and modular toolkit for mcts-based RL. Building on top of the JAX library, my toolkit allows researchers and practitioners to define and adapt various components of the reinforcement learning pipeline with ease and enables the exploration of a wide range of problem domains and environments. Muax achieves high performance by implementing the algorithm, neural network and a set of utilities, all of which are compiled just-in-time to run on accelerators.
SYSTEM DESIGN
Muax is built around the principles of modularity, extensibility, and usability. To facilitate these principles, Muax decomposes the components in the MuZero algorithm and implements entire reinforcement learning pipeline.
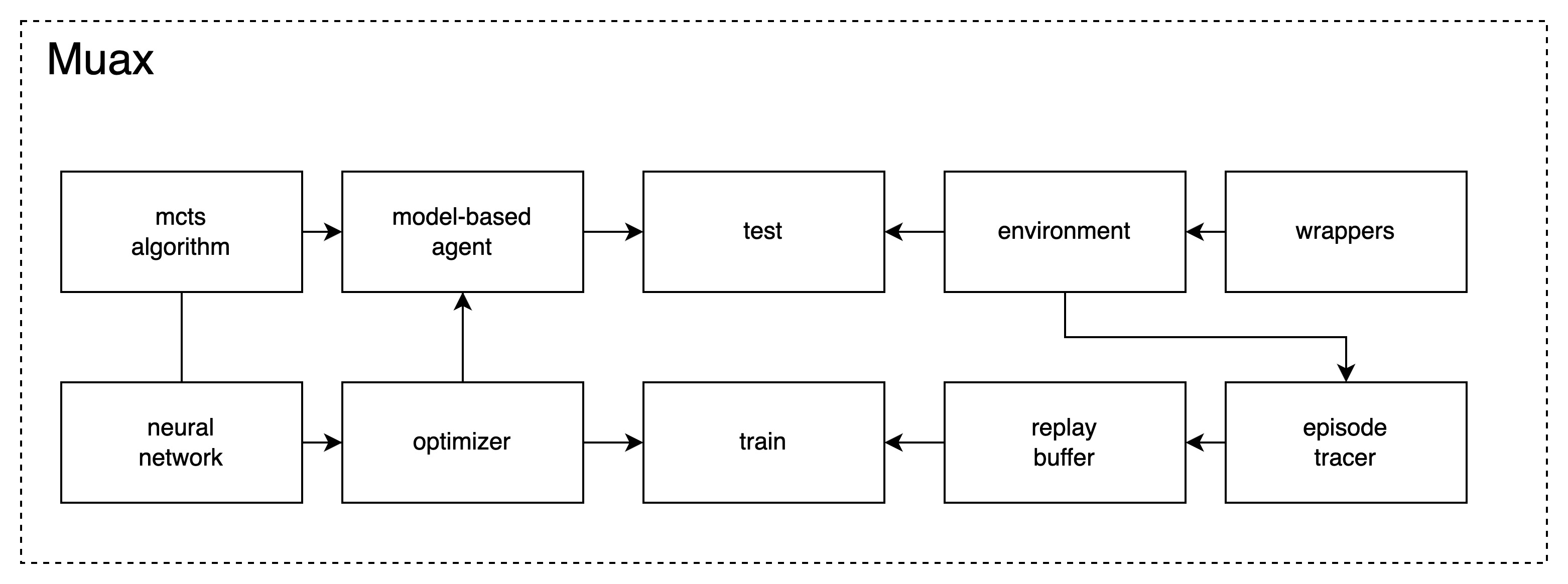
In this section, I provide an overview of the key elements and components of MUAX. Fig.1 is a graphical overview of each components. There are 10 components, which can be divided into 3 groups, namely model, training/testing and environment.
Model:
Muax decomposes the MuZero algorithm into tree search policy, neural network and optimizer.
- Model class: This class serves as the primary interface as reinforcement learning agent does, which interacts with the environment. It is responsible for managing the model's representation, prediction, and dynamics functions and their parameters, as well as the optimizer and the optimization process. Model class also controls which tree search policy to use. Users can customize the model by providing their own implementation of each functions or using the default ones provided by the framework.
- Tree search policy: Muax uses mctx as tree search policy. Through model class interface, the user specifies which policy to use. The tree search by mctx is fully compiled just-in-time and runs in parallel, making the process very efficient.
- Neural network: Muax uses haiku to build neural networks. The networks are used for Representation, Prediction, and Dynamic classes. These classes are used to build the major functions for tree search policies. As the name suggested, Representation is for encoding the raw observation into hidden state, Prediction is for evaluating the state and generates the prior action logits and Dynamic is for transferring the hidden state into the next state and calculates the reward associated with the transfer. By separating these functions, Muax promotes modularity and simplifies the process of customizing the model.
- Optimizer: Muax uses optax to build optimizer. The loss function can be provided through Model class interface. Therefore, Muax makes it easy to design and experiment with customized loss.
Training/Testing:
Muax employs a flexible training and testing loop. The main training loop is implemented in the fit function, which takes care of environment interaction, model training, and performance monitoring. Users can customize the training loop by providing their own implementation. Meanwhile, the testing loop is a simple interaction with the environment with trained model. The training and testing loop are both close to the typical loop for model-free algorithms, which makes it easy for RL practitioners to get started.
- Episoder Tracer: This module is responsible for temporarily handling step-wise data collected through interaction with the environment. The NStep and PNStep classes calculate the n-step bootstrapping and prioritized weight, respectively. Users can customize the behavior of these components to suit their specific requirements.
- Trajectory Replay Buffer: This module is responsible for handling trajectories' data. The ReplayBuffer class stores the collected data and provides the interface for sampling data.
Environment:
Muax is designed to be compatible with Gym environments, allowing users to train and evaluate their models on a wide range of tasks. The framework provides utility functions for easily wrapping Gym environments, enabling seamless integration with the training loop. Additionally, Muax will support the use of vectorized environments for more efficient training and evaluation.
Any implementations that are compliant with the interfaces defined by Muax can be seamlessly integrated.
MUAX EXAMPLES
Control tasks are classical reinforcement learning tasks and the Cart Pole is probably the first task the beginner solves. The purpose of these examples is to let users be familiar with Muax usage. In the Cart Pole example, there is also an end-to-end training example that demonstartes how to build customized pipeline from scratch.
a. CartPole. The CartPole task is a classic reinforcement learning problem, where the agent must balance a pole on a moving cart. This example illustrates how a task is implemented from scratch and integrated into Muax’s pipeline. Muax solves the CartPole-v1, a harder version of the environment within minutes.
b. Lunar Lander. This environment is a classic rocket trajectory optimization problem. This example illustrates that it is easy to wrap gym environments.

EXTENDING MUAX
Muax is designed to be flexible and extensible, allowing users to adapt the framework to various reinforcement learning tasks and requirements easily. With Muax it is possible to explore more effective neural networks, test novel loss functions, and experiment with customized environments. The customized modules can be integrated into Muax seamlessly if the interfaces are properly implemented.
Customize Model Components:
Users can implement customized components, for instance, representation, prediction, and dynamic functions by extending the corresponding base classes from the muax.nn module and providing their own implementation for the __call__ method. This enables users to create custom models with different architectures.
from muax.nn import (Representation,
Prediction,
Dynamic)
class CustomRepr(Representation):
def __call__(self, x):
# Implement custom method
return out
class CustomPred(Prediction):
def __call__(self, x):
# Implement custom method
return out
class CustomDynamic(Dynamic):
def __call__(self, x, a):
# Implement custom method
return out
Customize Loss Function:
The loss function plays an important role in algorithm training. Some work obtains better performance through loss function designs. Suppose we want to use a custom loss function for training the model. We can achieve this by defining a new loss function and passing it to the MuZero class as an argument:
def custom_loss_fn(model,
batch,
params):
# Compute the custom loss
# based on the model, batch,
# and parameters
# ...
return custom_loss
model = muax.MuZero(
...,
loss_fn=custom_loss_fn
)
Customize Environments and Wrappers:
To use custom environments or apply additional functionality to existing environments, users can create their own environment classes by extending the gym.Env class and implementing the required methods:
import gymnasium as gym
class CustomEnvironment(gym.Env):
def __init__(self):
# Initialize the custom
# environment
pass
def step(self, action):
# Implement the custom
# step logic
return obs, reward, done, info
def reset(self):
# Implement the custom
# reset logic
return init_obs, info
Additionally, users can create custom wrappers to modify the behavior of existing environments:
class CustomWrapper(gym.Wrapper):
def __init__(self, env):
super().__init__(env)
def step(self, action):
# Modify the step method
# as needed
return super().step(action)
def reset(self):
# Modify the reset method
# as needed
return super().reset()
These extension mechanisms empower users to easily adapt Muax to address various reinforcement learning tasks and requirements, facilitating the development of customized algorithms and techniques.
Learn more about MUAX through my blog Adding MuZero into RL Toolkits at Ease or from the github repo